The cache that couldn't cache
A homelab node pinned its memory and my portfolio pod climbed to 20 GB of RAM in a day. My first thought was an attack. It wasn't — it was two of my own caches failing silently, and normal traffic doing the rest. A war story about telling a leak from a breach.
AI-assisted postDrafted with help from Claude, edited and fact-checked by Mart. See transparency policy →
The Danaïdes (John William Waterhouse, 1903) — daughters condemned for eternity to carry water in jars that leak as fast as they fill. A cache that can't keep what you pour into it has the same job, and the same ending. Public domain.
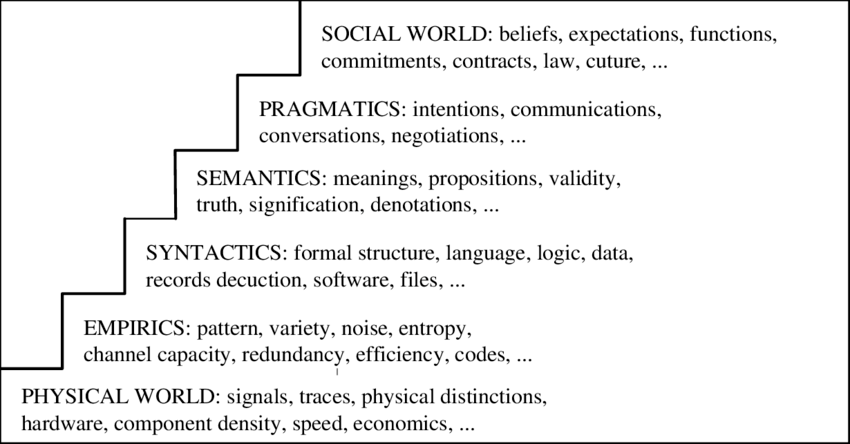
flowchart TD
REQ["Visitor request — ~8/hour, perfectly normal"] --> SSR["Next.js SSR render"]
SSR --> FETCH["Fetch ALL posts from Ghost: limit=all, full HTML ≈ 2.7 MB"]
FETCH --> CACHE["Next.js data cache: entry > 2 MB → rejected, never stored"]
CACHE --> HEAP["Response held in the heap, not freed"]
HEAP -->|every render repeats the same fetch| SSR
HEAP --> OOM["RAM climbs ~20 GB / 24h → cgroup OOM kill"]
%% solid = healthy, red = the failing link, slate = the damage it causes
classDef good stroke:#a3be8c,stroke-width:2.5px
classDef bad stroke:#bf616a,stroke-width:2.5px
classDef dead stroke:#7b88a1,stroke-width:2.5px
class REQ,SSR good
class CACHE bad
class FETCH,HEAP,OOM dead
The loop. Each render re-fetches the same 2.7 MB it is not allowed to cache, and holds it. Normal traffic is enough to fill 20 GB.
A node on my k3s cluster was pinned at maximum memory. I opened btop, found a node process near the top of the RAM column, and killed it. It came back. That is when the real question arrived, and it was not a technical one — it was a worried one: is someone doing this to me?
This is the story of answering that question, which turned out to be most of the work. The bug itself was two of my own caches failing in the quietest way a cache can fail: by not caching, and not telling anyone.
A number is not a diagnosis
"Maximum memory" is an alarm, not a cause. The first job is to turn the alarm into a name. Don't guess — make the machine tell you what the process is.
$ ps -eo pid,ppid,user,rss,cmd -C node
1416778 ... 160068 node current/index.js
2665887 ... 356744 node /app/node_modules/.bin/next start -p 3000
A next start. But "a Next.js process" is still not a name — on a k3s box, every pod's process shows up on the host like any other. So walk the parents:
$ pstree -sp 2665887
systemd───containerd-shim───bun───node(2665887)─┬─{node}─┬...
containerd-shim is the tell: this is a container, not a stray system daemon. The 18 {node} children in curly braces are V8 worker threads, not a fork bomb — a detail worth knowing so you don't chase the wrong shape. Reading the shim's command line gave the container ID and namespace, and crictl turned that into a pod name: portfolio — my own site. Killing the host process did nothing useful because Kubernetes simply restarted the pod; the controller was doing its job.
So: not a rogue binary, not something I didn't deploy. My portfolio. Which made the worried question sharper, not softer — because if it's my own app eating 20 GB, who is feeding it?
"Maximum memory" is not "under attack"
Here is the instinct worth correcting, because I had it too: a resource maxing out feels like an attack. It usually isn't. An attack is a hypothesis, and hypotheses get tested, not assumed.
First, the boring, important check — did anyone actually log in?
$ last -aF | head
me pts/0 ... 192.168.1.x
me pts/0 ... 192.168.1.x
...
Every session: me, from one LAN address. No foreign IPs, no root logins, nobody I didn't recognize. The SSH surface was clean. Good — but that only rules out a logged-in intruder, not abusive traffic. So I went to the edge proxy and counted who was actually hitting the site:
$ kubectl logs -n ingress deploy/caddy --since=168h \
| jq -r 'select(.request.host=="mysite.example") | .request.client_ip' \
| sort | uniq -c | sort -rn | head
110 203.0.113.x # me (home IP)
39 198.51.100.x
14 192.0.2.x
10 198.51.100.x
4 192.0.2.x
...a long tail of 1–2 each, many countries
There is a trap in reading this. My site sits behind a tunnel, so at first glance every request appeared to come from one internal 10.x address — the tunnel's own exit. That is not a suspect; it's the pipe. The real client lives in the forwarded header (X-Forwarded-For), which is the field jq is pulling above. Read the pipe instead of the header and you will "discover" that one IP is making all your traffic and waste an hour on it.
Read the right field and the verdict is plain: the busiest visitor after me made 39 requests in seven days. The rest is a scatter of search crawlers — Bingbot, a Moz crawler, the usual. No flood. No single hammering IP. No /_next/image abuse. A grand total of ~135 visitors in a week, hitting blog posts and robots.txt like any small site.
And that is the moment the case actually breaks:
[!NOTE] The memory climbed ~20 GB in a day on roughly 48 requests per day. No attacker doing two requests an hour pushes 20 GB. A leak that grows on your own ordinary traffic is a bug, not a breach. The crawler didn't break anything — it just kept tripping a tripwire I had left in my own code.
The cache that couldn't cache
With "attack" ruled out, I tailed the pod's own logs while it climbed, and the cause was sitting in plain text, repeated hundreds of times:
Failed to set Next.js data cache for
https://ghost.internal/.../posts/?...&limit=all...
items over 2MB can not be cached (3650448 bytes)
My blog content lives in Ghost, fetched at render time. Every list view — the blog index, each tag page, the "read next" block — called the API with limit=all and pulled every post with its full HTML body: about 2.7–3.6 MB of JSON. Next.js has a 2 MB ceiling on a single data-cache entry. Over that, it refuses to store the response — and then, because the page still needs the data, it fetches the whole thing again on the next render, and holds it in the heap while it works.
So the cache wasn't slow or stale. It was absent. Every render re-pulled multiple megabytes it was structurally forbidden from keeping, and under a trickle of crawler traffic that was enough to climb to 20 GB. The "first time ever" was not an event — my blog had simply grown past 2 MB, and crossed a threshold that had been waiting there the whole time.
The fix is to stop fetching what list views never use. A card needs a title, slug, excerpt, and image — not the post body. Ghost takes a fields= filter:
// before: every post, full HTML, ~2.7 MB, uncacheable
'/posts/?include=tags&filter=visibility:public&limit=all'
// after: card fields only, ~0.5 MB, comfortably under the 2 MB cap
const LIST_FIELDS =
'id,slug,title,excerpt,feature_image,published_at,updated_at,reading_time'
'/posts/?include=tags&fields=' + LIST_FIELDS + '&filter=visibility:public&limit=all'
2.7 MB became 512 KB. Under the ceiling, it caches, and the re-fetch loop is gone. Single-post pages still pull the full body — they're one post, and small.
The second cache, which couldn't write
I shipped that, watched memory, and it still climbed — slower, but up. The logs had a second confession I'd skimmed past:
⨯ unhandledRejection: Error: EACCES: permission denied,
mkdir '/app/.next/cache/images'
⨯ Failed to write image to cache ...
This one is a different failure with the same shape. The pod runs as a non-root user (good), but the image was built as root, so /app/.next was owned by root and the runtime user couldn't write to it. Next.js's image optimizer optimizes an image, goes to spill it to its on-disk cache, gets EACCES, and — unable to evict to disk — keeps the optimized bytes in memory. A disk cache that can't reach the disk doesn't fall back gracefully; it accumulates in RAM.
The first leak was a cache that refused an oversized entry. The second was a cache that couldn't reach its backing store. Both present identically: memory that only ever goes up. The fix was ownership, one line in the Dockerfile:
RUN bun run build \
&& mkdir -p /app/.next/cache \
&& chown -R bun:bun /app/.next
Now the optimizer writes to disk, evicts on its own schedule, and memory stays bounded — because eviction is what makes a cache a cache.
The shape of the bug
Strip away the specifics and both leaks are the same sentence: a cache that cannot store falls back to holding, and holding without eviction is just a leak with a respectable name. One couldn't store because the entry was too big; one couldn't store because the disk was unreachable. Neither raised an error you'd notice — they logged a line and carried on, and the heap did the rest.
The investigation taught me more than the fix did. A maxed-out resource pulls you toward the dramatic explanation, and "I'm under attack" is the most dramatic one available. But the cheap, decisive checks — what is this process, who is actually talking to it, does the math even work — almost always point somewhere quieter and closer to home. The SSH log was clean. The traffic was a handful of readers and some bots. The 20 GB was mine, fed by my own caching, two megabytes at a time.
[!TIP] When something grows without bound, don't start by asking who's attacking you. Ask what's supposed to be capping it. A queue with no consumer, a cache with no eviction, a buffer with no flush — find the thing that should bound it and you'll usually find it failing in silence.
Read next