Apache Fluss: making the stream queryable
Kafka was never built to be queried. Apache Fluss bolts a columnar, Arrow-native hot store onto the streaming layer and tiers cold to Iceberg — a clean full-stack realtime design whose only real open question is governance.
AI-assisted postDrafted with help from Claude, edited and fact-checked by Mart. See transparency policy →
The Amazon from orbit — a stream that never stops, branching and pooling into still water as it goes. Fluss is German for "river," and the shape fits: keep the flow moving, let history settle into the lake. Image: NASA, public domain.
Kafka1 was never a database. It is a row-oriented, append-only log, and it is superb at exactly that: durably accepting events and handing them back in order. The trouble starts the moment you want to query what is in it. There is no way to read one column without scanning whole records, no point lookup by key without replaying a partition from the beginning, and no analytical access at all. So the standard move is to ship the stream into a lakehouse2 and query it there — which means you pay for an extra hop, extra storage, and a freshness lag measured in minutes. Apache Fluss is a bet that you should not have to. It is a streaming storage layer that keeps the log's real-time guarantees but stores the data in a columnar, queryable shape from the start.
🔗 Learn more — 1 What is Apache Kafka?
🔗 Learn more — 2 What is a data lakehouse?
Kafka's blind spot
The reason Kafka cannot serve analytics is structural, not a missing feature. A log stores each record as an opaque, row-oriented blob, because that is what makes sequential append and replay fast. Analytics wants the opposite: read a few columns across millions of rows, skip everything else. That is the same OLTP-vs-OLAP split that splits the rest of the data world, and a log sits firmly on the wrong side of it for queries.
So you bolt on a pipeline: stream into Kafka, run a job that batches records into Parquet3, land them in an Iceberg4 table, and query that. It works, but you are now running two systems, storing the data twice, and your "real-time" dashboard is as fresh as your batch interval. For a lot of use cases that is fine. For genuinely real-time analytics it is the thing Fluss is trying to delete.
🔗 Learn more — 3 How Parquet works: columnar storage explained
🔗 Learn more — 4 How Apache Iceberg actually works
How Fluss works
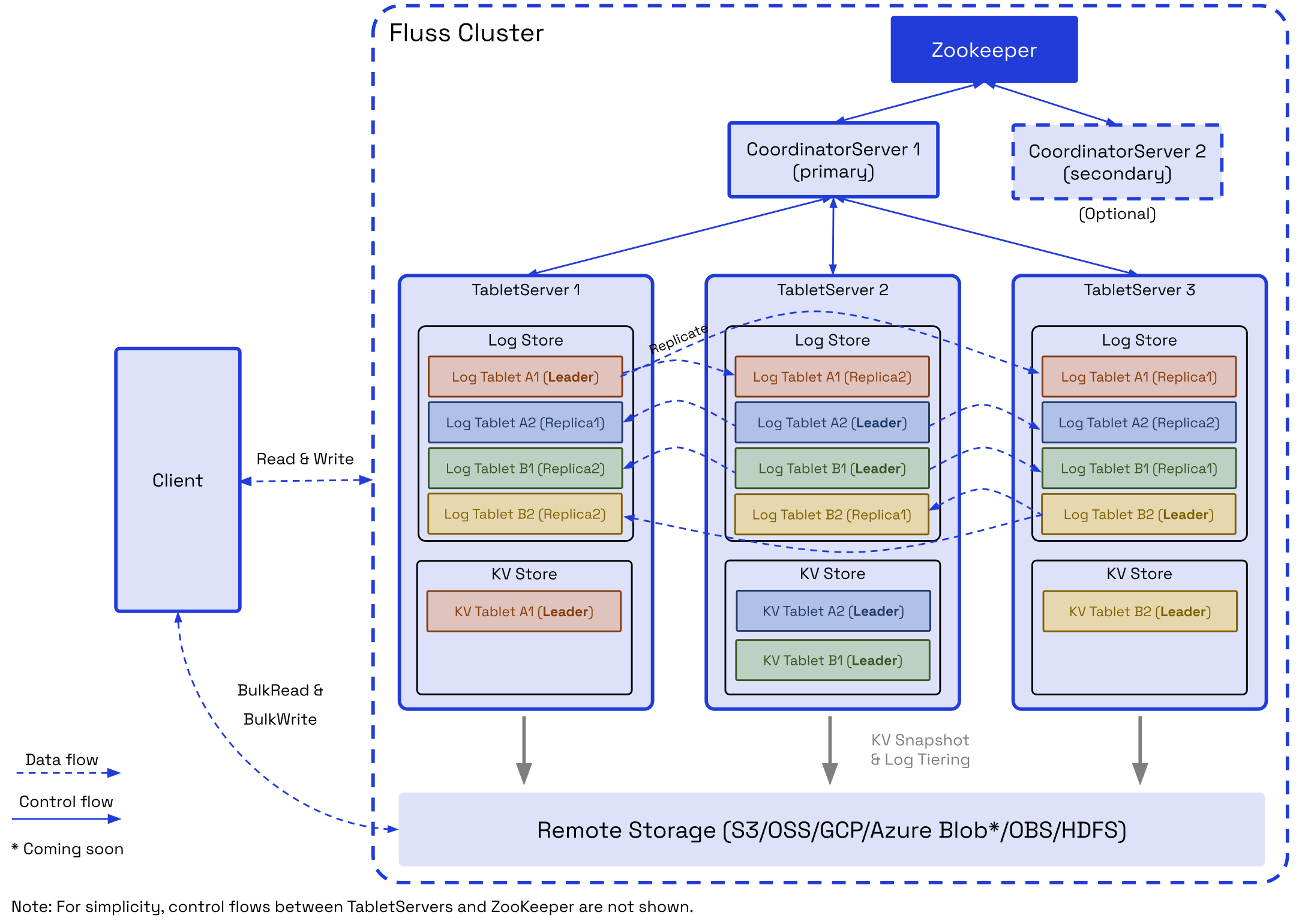
Apache Fluss 0.9 cluster: a client reads and writes against the TabletServers — each holding a LogStore (append-only log + WAL) and a KvStore (mutable state), replicated — coordinated by the CoordinatorServer and ZooKeeper, while the TabletServers offload to remote storage. Source: Apache Fluss documentation.
The architecture diagram above shows the shape. A CoordinatorServer runs the control plane — metadata, coordination, failure recovery — with ZooKeeper alongside (a Raft-based replacement is on the roadmap). The data lives on TabletServers, each holding two stores: a LogStore, the append-only log that serves low-latency streaming reads and doubles as the write-ahead log, and a KvStore (RocksDB) that materializes mutable, point-lookup-able state for primary-key tables and is rebuilt from the LogStore. Both are hot and in-cluster; only older log segments and KvStore snapshots offload to remote storage for cost and durability. The data is held in Apache Arrow's columnar format, so a reader prunes to just the columns it needs — the thing a Kafka log fundamentally cannot do. Fluss exposes two table types: Log tables (append-only, like a topic) and PrimaryKey tables (upsert, delete, and point lookup by key).
The standout feature is Delta Joins. Streaming joins in Flink5 are notorious for state blowup — both sides of the join accumulate in local state that can balloon into terabytes. Because a Fluss PrimaryKey table is a queryable, indexed store, Flink can look up against it instead of materializing that state. Alibaba reports a production case where this took a join's state from 100 TB to zero, cut checkpoint time from 90 seconds to 1 second, and dropped Flink resource usage by 85%. That is not a marginal optimization; it is the kind of number that justifies a new system on its own.
🔗 Learn more — 5 What is Apache Flink?
Hot and cold, one table
The part that matters most — and the part people get wrong about Fluss — is that it does not query from object storage on the hot path. Fresh data lives on the Fluss servers' local disks and is served from there with sub-second latency. A stateless tiering service periodically batches that data, converts Arrow to Parquet, and writes it to a cold data lakehouse table — Iceberg, Paimon, or Lance. A union read then presents both tiers as a single table, coordinated by offset so nothing is double-counted, and recent data ages out of the hot tier on a TTL once it is safely in the lake.
This is worth dwelling on, because it is the right shape. You are not hammering S3 with millions of tiny reads on every query — the antipattern that makes naive lakehouse-on-object-storage setups slow and expensive. You are serving hot data from a fast local store and keeping durable history in the lake, presented as one logical table. It is the hot-store-plus-durable-lake split done deliberately, with the duplication confined to a short freshness window rather than maintained forever. If you are skeptical of "just query everything off the bucket" architectures — I am — this is the version that actually respects how object storage behaves.
Two different object stores are in play here, worth keeping straight: the cluster's remote storage holds Fluss's own Arrow data — offloaded log segments and KvStore snapshots — for cost and durability, while the lakehouse tier is an open Iceberg (or Paimon/Lance) table the tiering service writes in Parquet for outside engines. One is Fluss talking to itself; the other is Fluss publishing to the open ecosystem. The diagram below is that second layer.
flowchart TD
CLUSTER["Fluss cluster"] --> TIER["Tiering service"]
TIER --> LAKE["Iceberg lakehouse"]
READER["Query engine"] --> CLUSTER
READER --> LAKE
EXT["External Iceberg engine"] --> LAKE
READER -. "Delta Join lookup" .-> CLUSTER
classDef plain stroke:#7b88a1,stroke-width:2.5px
classDef key stroke:#a3be8c,stroke-width:2.5px
class CLUSTER key
class TIER,LAKE,READER,EXT plain
The lakehouse layer: a tiering service compacts the cluster's data into an open Iceberg table. A query engine6 reads fresh data from the cluster and history from Iceberg as one table; any Iceberg engine can read the cold tier directly; and a Flink join can look up against the cluster instead of holding its own state.
🔗 Learn more — 6 What is a query engine (Trino, Presto, and friends)?
Not a Flink island
Early write-ups (and my own first assumption) pegged Fluss as Flink-only. As of the 0.9 release that is no longer true. Spark7 is now a first-class engine — catalog, plus streaming and batch read and write. Trino and StarRocks8 union reads are on the roadmap, and because the cold tier is plain Iceberg, any Iceberg-aware engine already reads the historical data for free.
🔗 Learn more — 7 What is Apache Spark?
🔗 Learn more — 8 What is StarRocks?
The client story is the surprising one. Fluss shipped Rust, Python, and C++ clients, all built on a single Arrow-native Rust core — so a Python data scientist gets zero-copy RecordBatches straight into Polars or DuckDB, no JVM in the client path. There is a clear roadmap toward a Rust query gateway speaking Flight SQL and Postgres wire, and an explicit nod toward Apache DataFusion integration to run SQL directly over Fluss. There is even an official Helm chart, which for a project this young is a pleasant surprise. The pieces of a genuinely multi-language, multi-engine platform are mostly in place.
Getting data in
Everything writes to Fluss through its client — available in Java, Rust, Python, and C++. Your application can embed that client and produce directly: AppendWriter for Log tables, UpsertWriter for PrimaryKey tables, no stream processor in the middle. There is no Flink or Spark requirement to get data in.
Flink and Spark matter when you want to pull from somewhere else. They are, in effect, pre-built Fluss clients with a connector ecosystem attached. Flink is the widest path: Flink CDC9 ships a dedicated Fluss sink, so streaming database changes — MySQL, Postgres, Oracle, MongoDB — straight into a queryable table is the canonical flow, and existing Kafka topics bridge the same way. Spark's Structured Streaming writer (0.9) does the same if you already live in Spark, with the caveat that it is micro-batch — second-ish latency, and none of the Delta-Join trick (that part is Flink-only).
🔗 Learn more — 9 What is Change Data Capture (CDC)?
The one thing you cannot do is point an existing Kafka or RabbitMQ10 producer at Fluss — it speaks its own protocol, not the Kafka wire protocol. A legacy producer either moves to the Fluss client or gets bridged through Flink or Spark. The client is just a library, not a broker — an app links it and talks to the cluster directly, and Flink and Spark are that same library with source connectors attached. Nothing sits in front of the cluster. The diagram below maps the paths.
🔗 Learn more — 10 What is RabbitMQ (and how is it different from Kafka)?
flowchart TD
APP["App"] --> CLUSTER["Fluss cluster"]
FLINK["Flink"] --> CLUSTER
SPARK["Spark"] --> CLUSTER
CDC["Database CDC"] --> FLINK
KAFKA["Kafka topic"] --> FLINK
RABBIT["RabbitMQ"] --> FLINK
KAFKA --> SPARK
RABBIT --> SPARK
classDef plain stroke:#7b88a1,stroke-width:2.5px
classDef key stroke:#a3be8c,stroke-width:2.5px
class CLUSTER key
class APP,FLINK,SPARK,CDC,KAFKA,RABBIT plain
Getting data in: an app writes straight to the cluster via the SDK; Flink and Spark connect directly too, bringing external sources like database CDC and Kafka. There is no broker in front — the engines are themselves clients.
Where it fits
Fluss is one entrant in a crowded fight to make the stream queryable, and the contenders attack it from different angles. The diskless-Kafka camp keeps the Kafka API and moves storage to S3; the streaming-database camp lets you run SQL on the stream directly; Fluss is its own category — a columnar streaming store.
| System | Approach | Lang / License | Cross-AZ cost | Columnar hot reads | Iceberg |
|---|---|---|---|---|---|
| Fluss | columnar streaming storage | JVM / Apache (incubating) | pays it (local-disk replication) | ✅ Arrow + PK + Delta Joins | tiers to it |
| AutoMQ | diskless S3-Kafka + table topics | JVM / Apache 2.0 | eliminated (S3-primary) | ❌ row log | Table Topic |
| WarpStream | diskless S3-Kafka | proprietary (Confluent/IBM) | eliminated | ❌ row log | via Tableflow |
| Redpanda11 | Kafka-compatible + Iceberg Topics | C++ / BSL (→Apache 2.0 after 4yr) | reduced | ❌ row log | Iceberg Topics |
| RisingWave | streaming database | Rust / Apache 2.0 | n/a (S3-backed) | ✅ SQL on stream | ✅ |
| Timeplus Proton | streaming DB on ClickHouse12 | C++ / Apache 2.0, no JVM/ZK | n/a | ✅ | partial |
🔗 Learn more — 11 What is Redpanda?
🔗 Learn more — 12 What is ClickHouse?
The sharpest tradeoff is hiding in the cross-AZ column. Fluss's hot tier replicates across nodes the way Kafka does, which means it inherits Kafka's real cloud cost: inter-AZ network fees are the bulk of a streaming bill, not storage. The diskless crowd — AutoMQ and the now-Confluent-owned WarpStream — eliminate that by writing straight to S3 with no replication. They pay for it with higher write latency and, crucially, no columnar hot reads: they are still row logs, just cheaper ones. Fluss spends the cross-AZ money to buy something they do not have — analytical reads and Delta Joins on the hot data. Whether that is worth it is exactly the question a buyer should be asking, and the honest answer is "only if you truly need sub-second analytics on the stream" — which is really a question about whether you need streaming at all.
The honest tradeoffs
Net, I think the tech is sound and the architecture is the one I would actually recommend for realtime-plus-lake. The reservations are real but mostly bounded:
- The server is still JVM, with ZooKeeper. A migration to KvStore-plus-Raft (Kafka's KRaft move) is planned, and the clients are already native Rust — but the data-plane engine stays on the JVM, with the GC and footprint that implies. For most corporate shops that is a tax they already pay happily; for the performance purist it is the ceiling.
- Cross-AZ replication cost, as above — the genuine operating-cost line, not S3 ops.
- PrimaryKey-table reads carry RocksDB overhead and run slower than Log tables.
- Schema evolution is partial. Adding columns landed in 0.9 — zero-copy, metadata-only, the same trick Iceberg uses — but it is append-at-end and nullable-only; rename, drop, reorder, and nested-field changes are still on the way.
- Youth. It is an Apache incubating project and the multi-language clients are at 0.1.0. It moves fast — features I assumed were missing turned out to have already shipped — but "incubating" is "incubating."
And then the one that is not technical at all: governance. Fluss was built by Alibaba and is commercialized by Ververica, which Alibaba owns. The project only just entered the Apache incubator. None of that is disqualifying — Iceberg started inside Netflix — but it is the open question. Iceberg won the table-format war on governance, not features, because no single vendor controlled it. The move that would make Fluss safe to bet on, especially for adopters outside its home market, is the same one: a clean graduation from incubation with committers from more than one company, so it reads as a neutral project rather than one vendor's house format. That is the milestone to watch.
But do you even need it?
Most teams do not, and that is the most useful thing to say out loud. The test is one question: if this data were an hour stale, would anything break or any money be lost? For most reporting, BI, and dashboards the answer is no — and then you do not need Fluss or streaming at all. Batch into Iceberg and query it with DuckDB, a single node, or a warehouse. Streaming infrastructure you do not need is just operational cost with a logo on it.
Where the answer is yes, Fluss is in its element:
- CDC into live materialized views — database changes streamed in and queried fresh; the headline case, and what Alibaba is migrating its internal Kafka to Fluss to do.
- Real-time dashboards and operational intelligence — logistics, manufacturing, ride-sharing, anything where the screen has to be current.
- Fraud and anomaly detection — where an hour of lag is the gap between blocking a transaction and eating the loss.
- Personalization, search, and ad attribution — sub-second features behind a live experience.
- Real-time feature stores for ML and AI — one fresh, queryable copy instead of separate online and offline layers.
Even then it is usually a handful of pipelines that need this, not the whole platform. The skill is knowing which ones — and leaving everything else in batch.
A short close
Strip away the noise and Fluss is a clean idea executed well: store the stream in a columnar, queryable shape; serve hot data fast from local disk; tier history to Iceberg; present it as one table. It leans on Apache Arrow as the in-memory lingua franca and Apache Iceberg as the on-disk one — and that is the quiet pattern worth noticing. The table-format war settled on a neutral format; the catalog war is settling on a neutral spec; now the streaming layer is being rebuilt on those same neutral interchange points. Whoever owns the most-trusted-because-least-owned pieces wins, one layer at a time. Fluss has the architecture. Whether it earns the trust is up to how it is governed from here.
Read next


